Teaching Poker with Machine Learning: How I Built a Three-Model Decision Coach

Last year, Jonathan Tamayo was accused of using a solver during the 2024 WSOP Main Event. The fallout led to a rule change from the world's most prestigious poker organization. The irony? Even if he had used one, most players wouldn't know what to do with the output. GTO solvers are powerful, but they're built for professionals who already think in ranges and equity percentages. They don't explain anything.
That gap is what this project tries to close.
The Problem with Learning Poker Today
Poker is having a moment. But the tools available to learners are stuck at two extremes: YouTube theory with no real feedback, or solver output that assumes you're already an advanced player. What's missing is something that can sit with a beginner mid-hand, tell them what to do, and actually explain why. That's what I set out to build for my CIS 508 final project.
You can try the live app here: Poker ML. It's deployed on Google Cloud Run, so give it a minute or two on the first load.
What Actually Separates Good Players from Bad Ones
Before writing a single line of model code, I wanted to understand what elite play actually looks like in the data. The answer surprised me a little. Weak players are more aggressive than elite ones at every point in a hand, especially preflop. They over-bluff with weak hands and push too hard with medium-strength ones. Elite players are selective. They know when to slow down.
That finding shaped the whole feature set. If the key behavioral signal is how players use aggression relative to their hand strength, position, and stack depth, those are the things the models need to see. The final feature set ended up covering 12 groups and around 79 features, including pot odds, stack-to-pot ratios, rolling aggression history over the last 3 to 10 hands, board texture, and draw flags.
Three Models, Three Sub-Problems
Instead of one monolithic model trying to do everything, I split the decision into three cooperating models. Each one has a specific job.
Opponent Range Model (Classification)
This one reads the betting patterns so far and predicts how strong the opponent's hand likely is: strong, medium, or weak. You really can't make good decisions without some kind of read on what you're up against.
Profit Model (Regression)
This model predicts expected value in big blinds before you act. It's not just about the hand you have right now; it's trying to capture the implied value of future streets too. The honest result is an RMSE of 21 to 24 big blinds, which is useful for direction but not precise enough for exact bet sizing. Poker profits depend heavily on hidden information, and the model simply can't see what the opponent is holding.
Policy Model (Classification)
This is the user-facing one. It takes the opponent read and the profit estimate, and recommends an action: Fold, Call, or Raise.
The Hardest Part: Designing the Target Variable
"A bad call that wins looks like good play in the data. A good fold looks like weakness."
This is where most poker ML projects quietly fall apart. The naive approach is to label whatever a winning player did as the correct action. But that bakes luck directly into your training data. So I built a rule-based correction layer. For any hand where the player lost or broke even, I replaced the label with what the correct action should have been, based on hand strength, stack-to-pot ratio, and position.
Strong hand with few chips left? The correct action is all-in. Decent hand in late position? Raise small. Unplayable cards with poor pot odds? Fold. It is not a perfect system since poker genuinely has multiple valid answers to the same spot, but it produces labels that reflect actual poker logic rather than just copying outcomes.
Architecture: Databricks, MLflow, and GCP
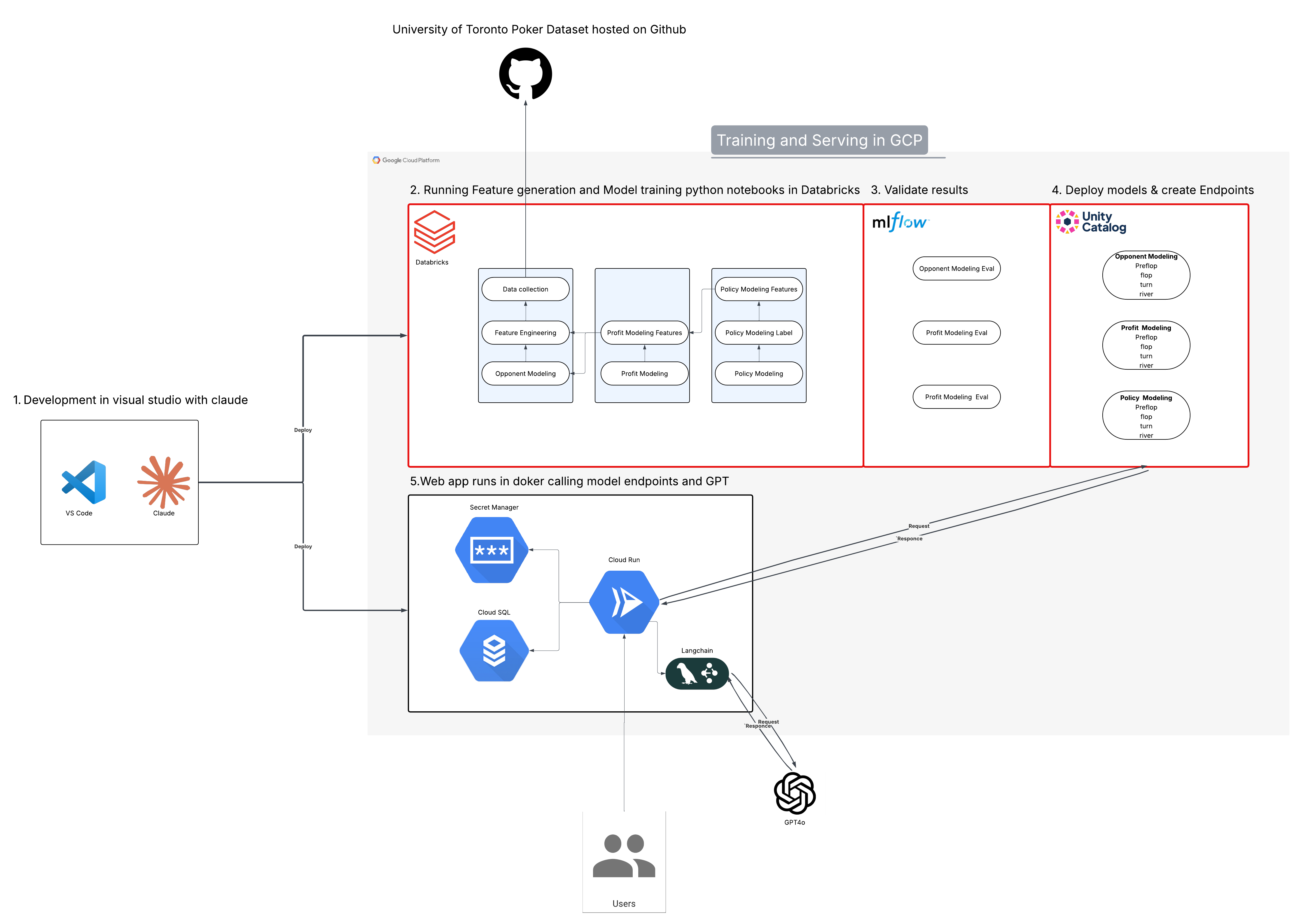
Training Pipeline
All feature engineering and model training runs in Databricks notebooks on GCP. The pipeline covers four streets (preflop, flop, turn, river) across all three model families, which adds up to 12 models total. MLflow handles experiment tracking throughout: every run logs hyperparameters, evaluation metrics, and artifacts so nothing gets lost between iterations. Once a model passes evaluation, it registers in Unity Catalog, which handles versioning and promotion to production endpoints. Having that structure made iterating across streets much less painful. Changing a feature in one notebook propagated cleanly without having to re-run everything from scratch.
Serving Layer
The web app runs in a Docker container on Cloud Run, which takes care of auto-scaling and cold starts. A Langchain orchestrator handles the routing logic: it calls the relevant model endpoints, interprets the outputs, and passes them to GPT to generate plain-English guidance for the user. Cloud SQL stores game state across a session, and Secret Manager handles credentials. Development was done in VS Code with Claude.
The end-to-end flow is: user inputs game state, Cloud Run routes the request to the right model endpoints, GPT translates the recommendation into plain English, and the response comes back to the user.
See It in Action
Watch the demo walkthrough: https://youtu.be/h1PYlyFoL-c
What the Results Actually Mean
The policy model's F1 score is lower than you'd want on paper. That is not really a failure of the engineering though; it is more a property of the problem itself. A high F1 score means the model is good at imitating common actions, not that those actions are profitable. A lot of hands end before showdown, so the training data systematically skips the most information-rich moments. And things like opponent tendencies and table dynamics are not in the data at all.
The honest version of these results: the models are useful for giving a beginner clear guidance on straightforward spots. On the messy, ambiguous ones, the model and an experienced player might land on different answers, and truthfully both could be right.
What I'd Build Next
The thing I'd most want to add is a real feedback loop. Right now the system gives advice but has no idea whether following that advice actually helped. Tracking outcomes over time and adapting recommendations to a user's actual skill trajectory would make it a much better coach.
I'd also want to move away from the rule-based target variable correction toward something learned, using a set of validated expert hands as a reference signal during fine-tuning.
The research space here is genuinely exciting. ReBel uses self-play and belief-state reasoning to reach superhuman performance in heads-up no-limit hold'em. SpinGPT treats poker like a language task and matches a strong solver about 78% of the time in three-player Spin & Go formats. Both projects point in the same direction: richer state representation and self-play are where the real ceiling is.
This project sits in a different lane. It is not trying to beat you at poker. It is trying to teach you.
The code is on GitHub: allllc/PokerML. Give the live app a shot: Poker ML. Just remember cold starts take a minute or two to spin up.